
“北极星”基础教育大模型评测场二期评测榜单发布:7大场景,升级模型迎来再对决
在市教委指导和市科委支持下,北京师范大学智能技术与教育应用教育部工程研究中心联合北京教育科学研究院和北京智源人工智能研究院共建“北极星”基础教育大模型评测场(www.bnueval.com),具备紧扣新课标、聚焦教育应用、多学科多场景的特点,是首个基础教育领域的大模型评测场。
继首期榜单发布后,“北极星”评测场面向近期更新的大模型开展新一轮评估与分析。2025年10月28日,发布并解读多款近期发布或升级的大模型在智能解题、智能答疑、智能出题、教案生成、口语练习、作文批改、学情分析7大场景下的评测结果。
本次评测结论与一期榜单基本保持一致,并增加以下详细分析:
1.通用模型迭代较快,教育模型仍处积累阶段。相比于一期榜单,本期评测的模型中,多个主流模型系列已完成版本替换或迭代升级,如GPT、Qwen、GLM等均推出更先进模型,整体能力更强。相比之下,教育模型更新频次较低,部分首期模型因版本未变未再测评,展现出教育模型仍处技术积累阶段的特点。
2.模型教育引导能力仍显不足,未能有效支撑核心素养导向教学。在出题、教案等任务中,模型在结构、逻辑等基础维度上表现稳定,但在素养导向、情境创设与启发引导等关键维度上得分普遍较低。这表明当前大模型虽具备完成教学任务的基础能力,但在内化新课标理念、服务素养导向教学等方面仍存在短板。
各场景深层洞察分析结果如下,完整榜单请登录官网查看(www.bnueval.com)。
一、教育专业能力评测榜单
教育专业能力聚焦初中解题场景,覆盖语文、数学、英语、物理、化学、生物、历史、地理、信息科技 9 大核心学科,包含客观题和主观题,依据新课标课程内容制定每门学科的细粒度评测维度。评测结果如下表所示。
表 1 语文学科智能解题的评测结果
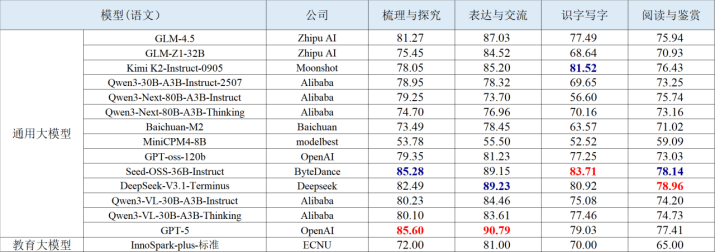
表 2 数学学科智能解题的评测结果
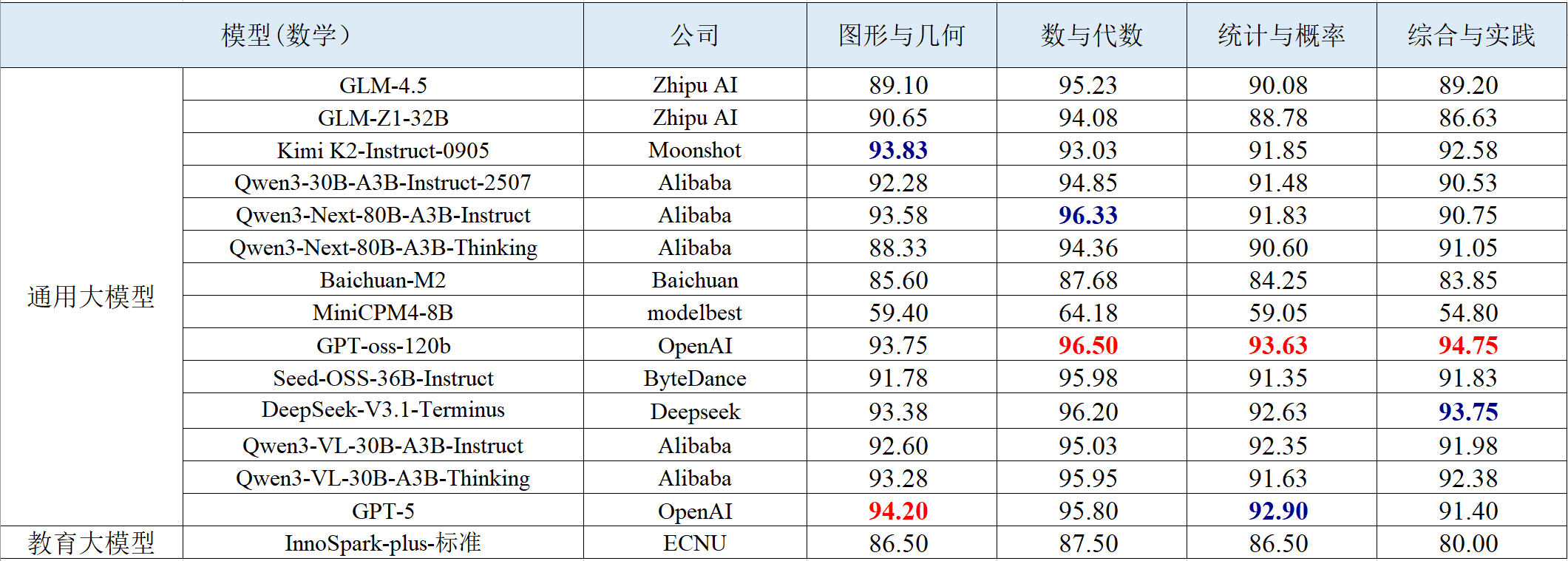
表 3 英语学科智能解题的评测结果
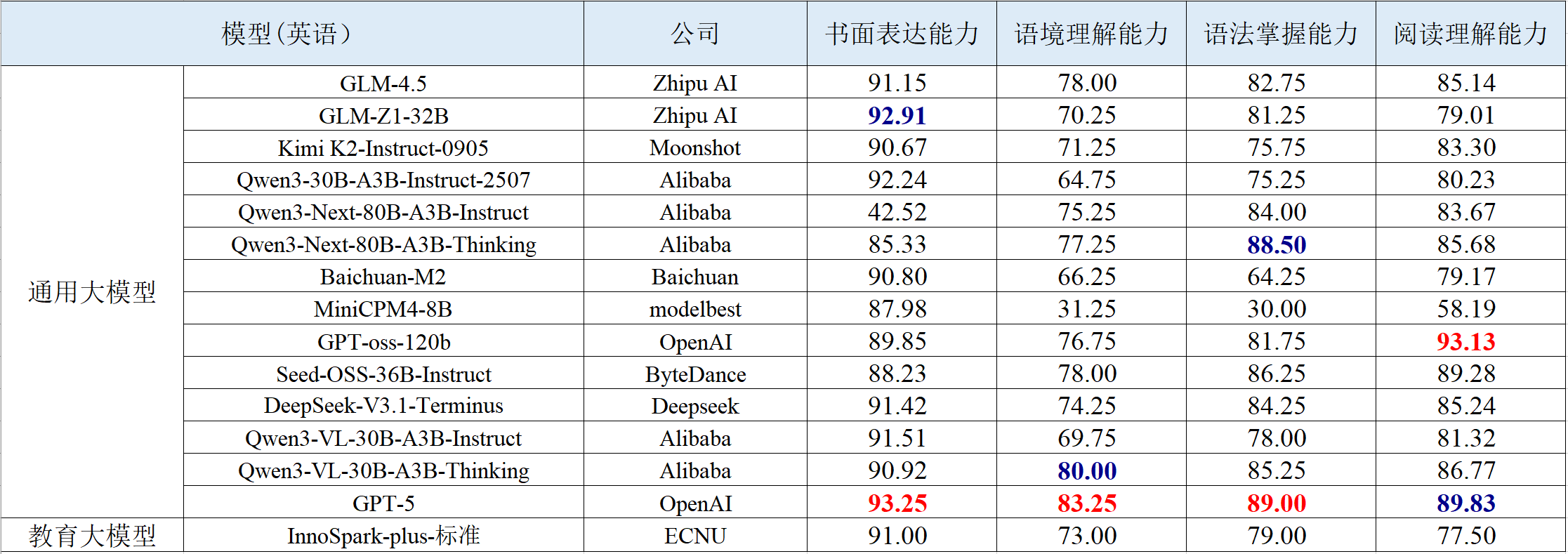
表 4 物理学科智能解题的评测结果
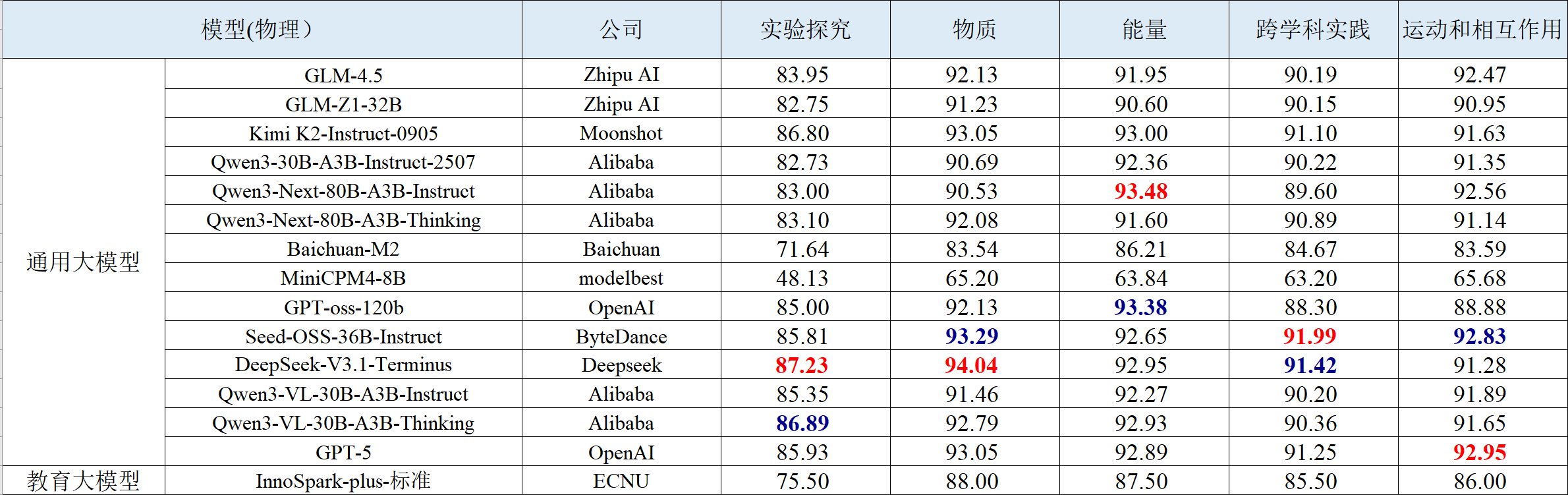
表 5 化学学科智能解题的评测结果
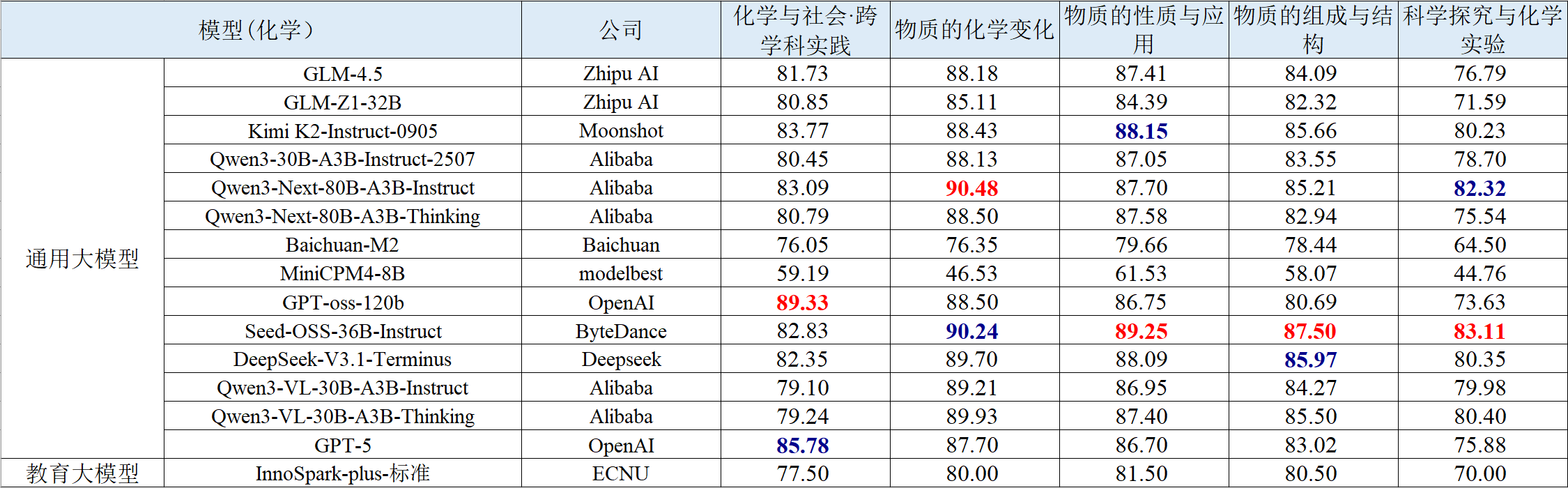
表 6 生物学科智能解题的评测结果
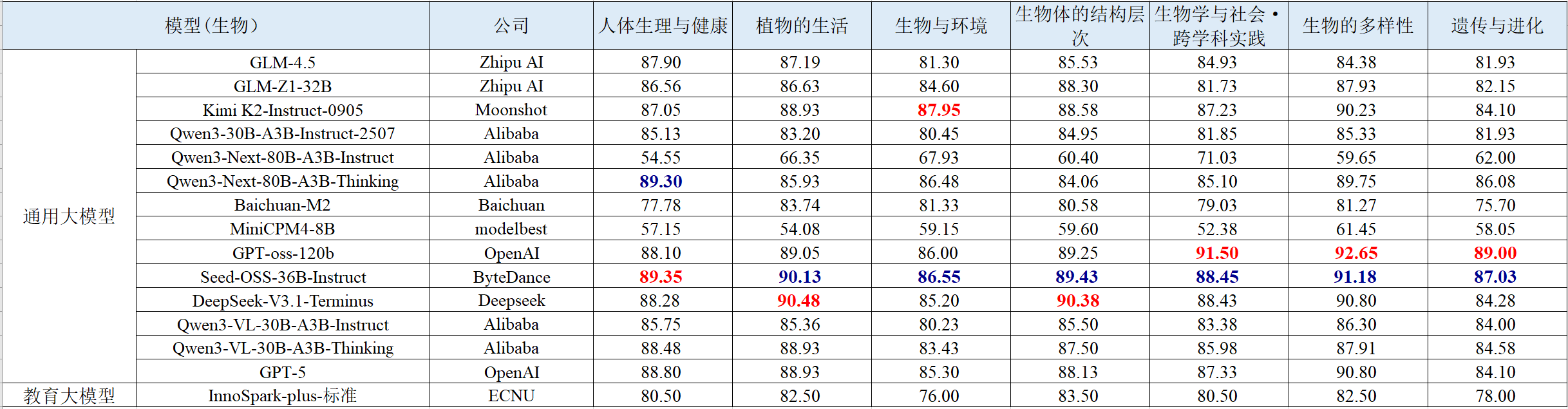
表 7 历史学科智能解题的评测结果
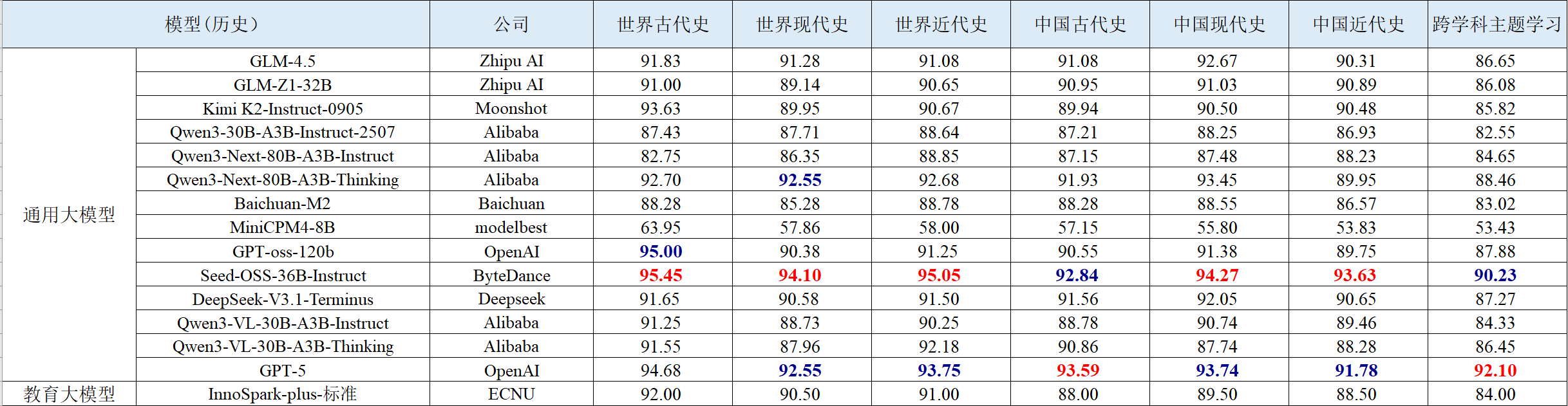
表 8 地理学科智能解题的评测结果
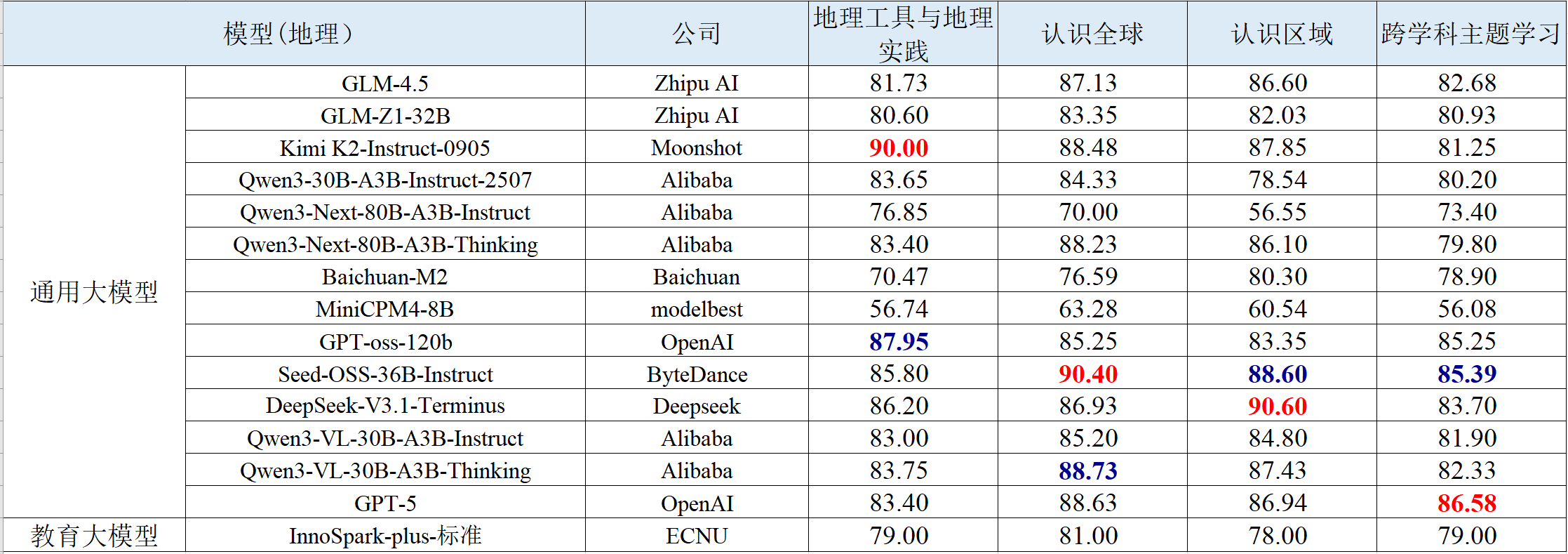
表 9 信息科技学科智能解题的评测结果
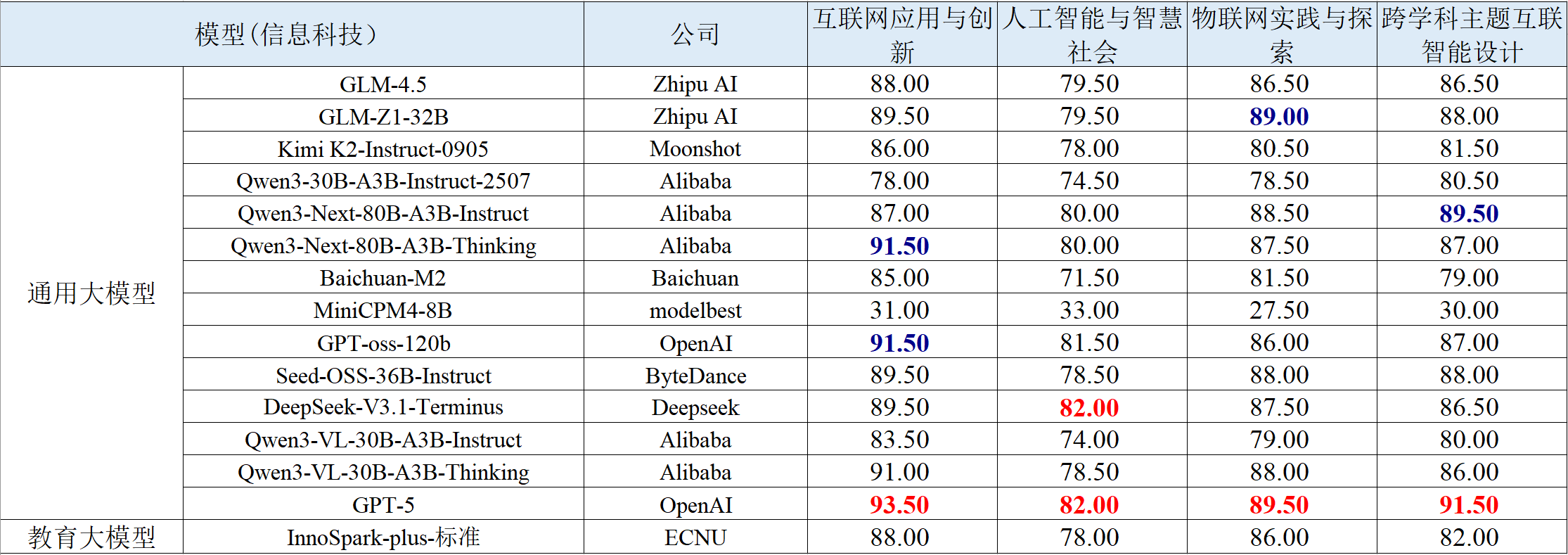
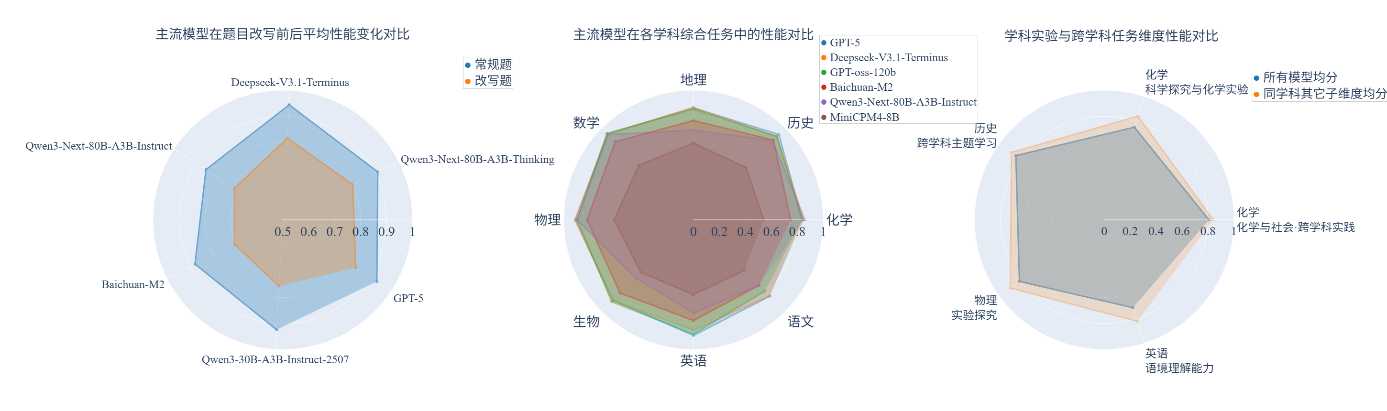
图 1教育专业能力部分评测结果可视化展示
(1) 在客观题的改写类题型中,各模型性能下降明显。与一期榜单保持一致,当客观题经过语义与结构上的重构后,几乎所有模型都出现性能下降的现象。GPT-5等具备更强语义理解与推理能力的模型在题目改写后,也表现出一定程度的性能衰减。
(2) 模型具备共通的核心能力。不同学科间模型能力呈现同增同减趋势,表明模型的任务表现依赖于统一的底层推理与知识建构机制。模型在任何单一学科上的表现,都根植于通用认知基础的整体水平,而非分学科式技能。
(3) 复杂情境化任务是模型短板。现有模型大多擅长解答有标准答案的知识类问题,但在需要主动探索、设计和构建知识的情境中则表现不佳。尤其在实验探究、交叉学科和复杂情景化任务中,模型难以将知识灵活迁移和应用,尚不具备在复杂真实情境中主动解决问题的能力。
二、教育应用能力评测榜单
1.智能答疑
智能答疑评测聚焦大模型在基础教育教学场景中的实际应用能力,涵盖数学、物理、化学三大学科,围绕内容质量、互动反馈、启发引导三大方向构建包含8个核心能力维度的评测体系。评测结果如下表所示。
表 10 数学/物理/化学学科智能答疑的评测结果
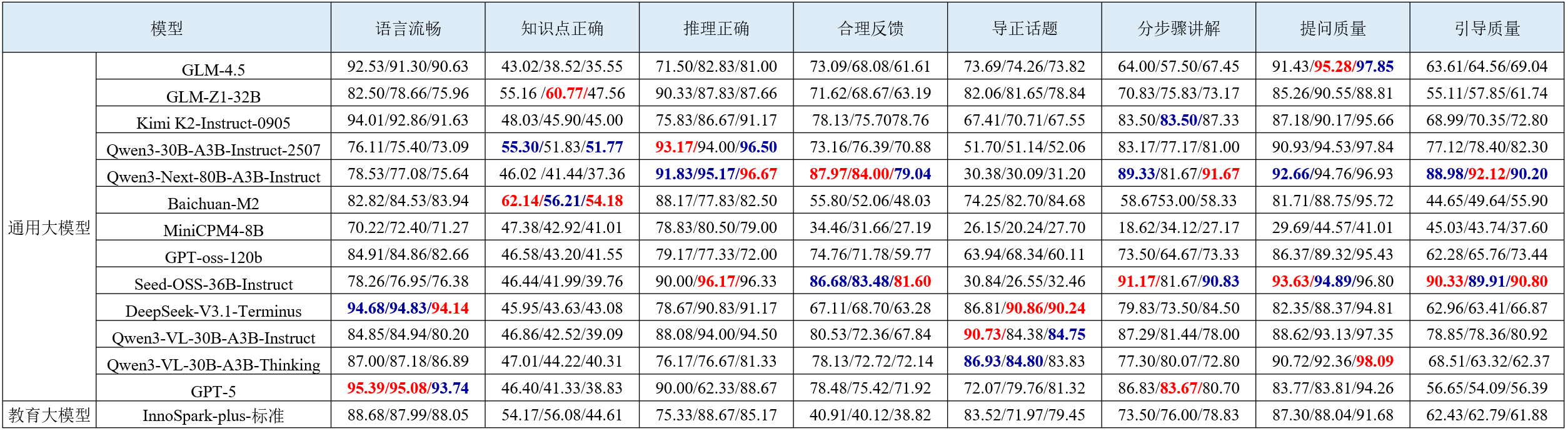

图 2 数学学科智能答疑部分评测结果可视化展示
(1) 相较首期榜单,多数模型在语言流畅和推理正确维度表现稳定,提问质量有明显提升,但知识点正确维度仍存在短板。具体而言,模型在语言表达与逻辑推理能力方面保持相对稳定;提问质量的提升表明模型在答疑过程中能够生成更具启发性的提问,从而有效激发学生思考。然而,模型在知识点正确维度上的得分依然普遍偏低,暴露出其在知识理解与识别能力方面的不足,在与新课标课程内容的衔接上仍存在局限。
(2) 多数模型在分步骤讲解维度上表现不错,但在导正话题维度上表现差异明显。具体而言,模型分步骤讲解得分普遍较高,表明模型能够进行逐步讲解,而非直接给出答案,其过程接近真人教师的答疑方式。然而,在导正话题维度上,各模型表现参差不齐。当答疑围绕具体题目逐步进行时,模型将学生偏离主题的回答引回核心解题思路的能力存在差异,显示出部分模型在维持答疑主题上存在不足,导正话题能力仍有待提升。
(3) 对比国内外同系列模型,Qwen系列最强模型在八个维度上的整体表现略优于GPT-5。具体而言,相较于GPT-5,Qwen3-VL-30B-A3B-Instruct在引导质量、提问质量和导正话题等维度表现更为出色,显示出其在逐步引导以启发学生思考和及时纠正学生话题偏离方面的潜力。然而,在语言流畅维度上,Qwen系列得分偏低,GPT-5在该维度仍保持领先优势。
2.智能出题
智能出题评测任务旨在从知识点匹配度、题型匹配度、题目准确性、解析准确性和素养导向性等维度全面评测大模型生成初中数学、物理和化学三门学科习题的能力。评测结果如下表所示。
表 11 数学/物理/化学学科智能出题的评测结果
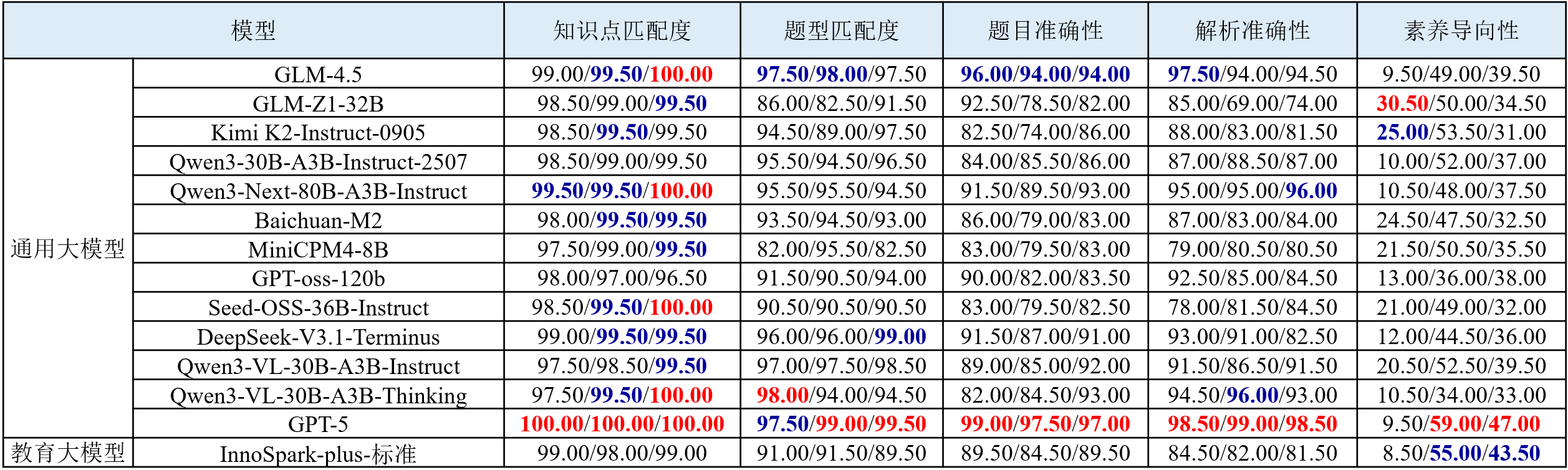
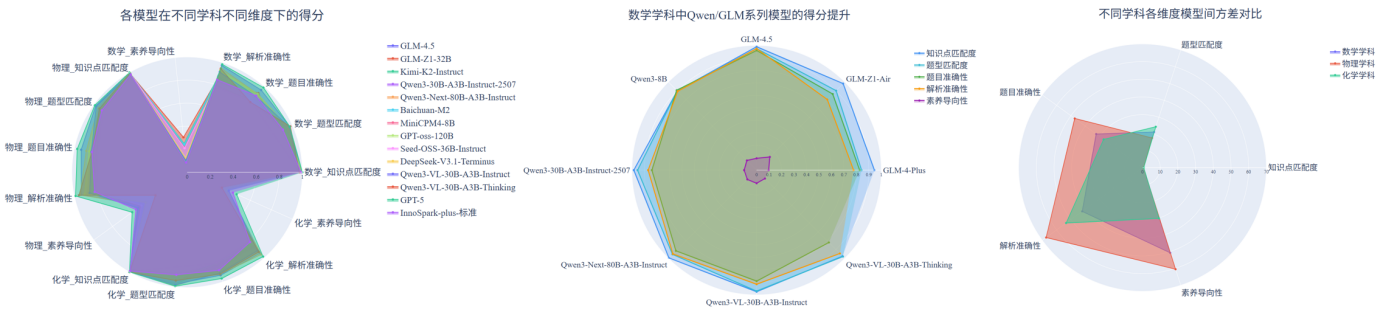
图 3 智能出题部分评测结果可视化展示
(1) 模型出题能力呈学科差异,在数学素养导向性上表现最弱。在物理、化学、数学三类学科题目中,模型在物理题的知识点匹配和题型匹配度上表现相对突出,化学题整体处于中等水平,而在数学题素养导向性上表现最弱。
(2) 国内主流系列模型在知识与解析能力上持续提升。与上一期榜单相比,国内头部模型在核心生成指标上普遍提升,特别是Qwen3系列在知识点匹配度与解析准确性维度上均稳步提升,其中Qwen3-Next-80B-A3B-Instruct在物理与化学学科的解析准确性上较之前的模型均有明显提升。此外,GLM-4.5相较于其前代GLM-4,也在所有维度上实现提升。
(3) 解析准确性与素养导向性成为拉开模型性能差距关键。不同模型在解析准确性与素养导向性上呈现出高方差,表明该维度是拉开不同模型能力差距的主要因素。相反,知识点匹配度与题型匹配度上方差较低,表明其并非是区分模型性能差异的关键点。与此类似,从学科维度看,不同模型在物理学科上差异显著,数学次之,化学较为稳定。
3.教案生成
教案生成评测任务旨在从结构完整性、内容准确性、内容一致性、语言逻辑性和素养导向性等维度全面评测大模型生成初中数学、物理和化学三门学科教案的能力。评测结果如下表所示。
表 12 数学/物理/化学学科教案生成的评测结果
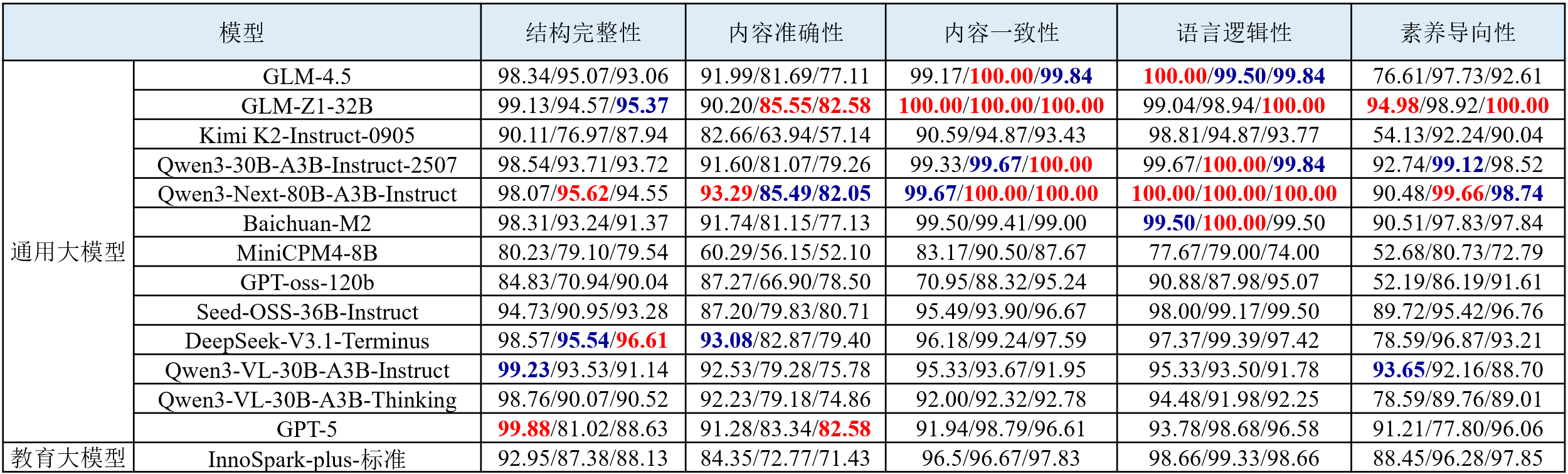
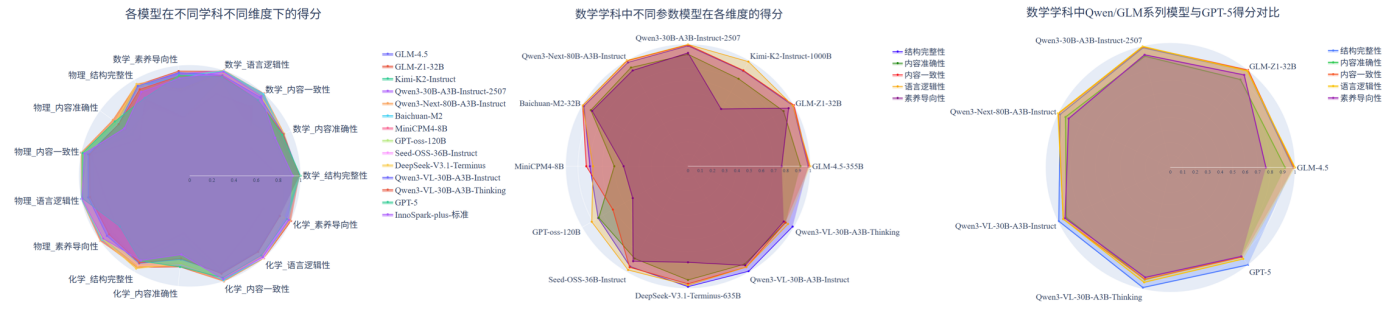
图 4 教案生成部分评测结果可视化展示
(1) 内容准确性仍为多数模型的薄弱项,亟待加强。在教案生成任务中,模型在结构完整性、语言逻辑性和内容一致性等维度上表现稳健,但内容准确性明显偏弱。物理和化学学科因对知识概念、计算与实验原理要求更高,模型在内容准确性上的得分显著低于其他维度;相较之下,数学准确性略高,但在素养导向性方面仍不足。
(2) 参数规模与性能正相关但非线性增长。中小规模模型在结构完整性与语言逻辑性方面已具备一定稳定性,但在内容准确性和素养导向性上性能明显不足。大型模型在结构完整性、内容一致性与语言逻辑性方面显著优于中小模型。然而,进一步扩大参数量的模型并未在所有维度上持续提升,部分通用大模型在素养导向性上提升有限。
(3) 国内模型持续进步,Qwen与GLM系列加速追平国际主流水平。Qwen系列与GLM系列等国内开源模型在结构完整性、内容一致性与语言逻辑性方面,已达到甚至超越GPT-5等国际旗舰模型水平,展现出国内大模型在中文教育语料微调与任务定制上的优势。
4.口语练习
口语练习评测任务旨在全面评估大模型在英语学科口语练习场景中的表现。评测任务的输入为学生真实语音及大模型的单轮回复,输出为待测大模型在发音准确性、流利度、韵律、语法准确表达、难度匹配学段、主题聚焦拓展、英文优先交互7个评测维度上的分数。评测结果如下表所示。
表 13 英语学科口语练习的部分评测结果
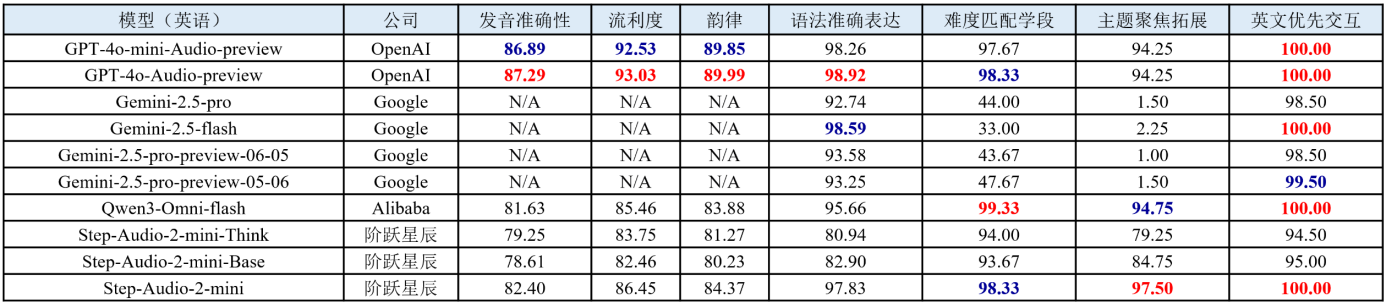
图 5 英语学科口语练习部分评测结果可视化展示
(1) 国际模型主导语音基础能力,国产模型在场景化指标实现反超。以 OpenAI 的 GPT-4o 系列为代表的国际模型,在发音准确性、流利度、韵律等语音核心维度上依旧保持技术领先优势。然而,以阶跃星辰(Step-Audio)、阿里通义(Qwen)为代表的国产模型,在主题聚焦拓展等直接影响用户对话体验的场景化指标上,正实现对国际模型的追赶和超越。
(2) 主题聚焦拓展成最大差异化维度,国产模型表现突出。Gemini系列在该维度的表现相对有限,虽然在文本任务上表现优异,但其技术并未能平滑迁移到需要高频互动的口语练习场景中。相比之下,国产模型如Step-Audio-2-mini和Qwen3-Omni-Flash在该维度上实现性能提升,尤其在对话连贯性和内容拓展能力上,展现出更好性能,提升了用户的口语训练体验。
(3) 口语场景中,“思考”推理机制可能带来负面影响。在口语练习场景中,配备“Think”推理版的模型在主题聚焦拓展和语法准确表达维度上的得分反而低于“Base”基础版。该现象揭示了口语任务的独特性:口语练习要求流畅、自然且即时的互动。虽然“思维链”机制能够增强模型的思考深度与生成逻辑,但其推理延迟与内容外延可能破坏交互流畅性,甚至导致主题偏移。
5.作文批改
作文批改评测聚焦大模型对中文作文及英文作文的批改能力。评测任务的输入为作文题干文本与学生作文图片,依据中考标准制定维度,输出主旨、逻辑、语言、想象力、书写、内容、组织、语法及评语评测维度的分数。评测结果如下表所示。
表 14 语文作文批改的部分评测结果
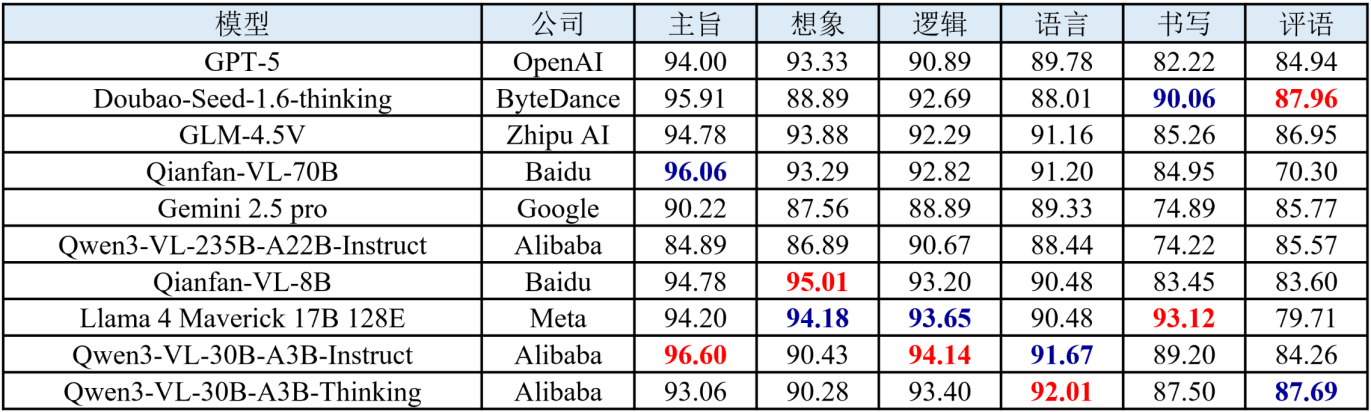
表 15 英语作文批改的部分评测结果
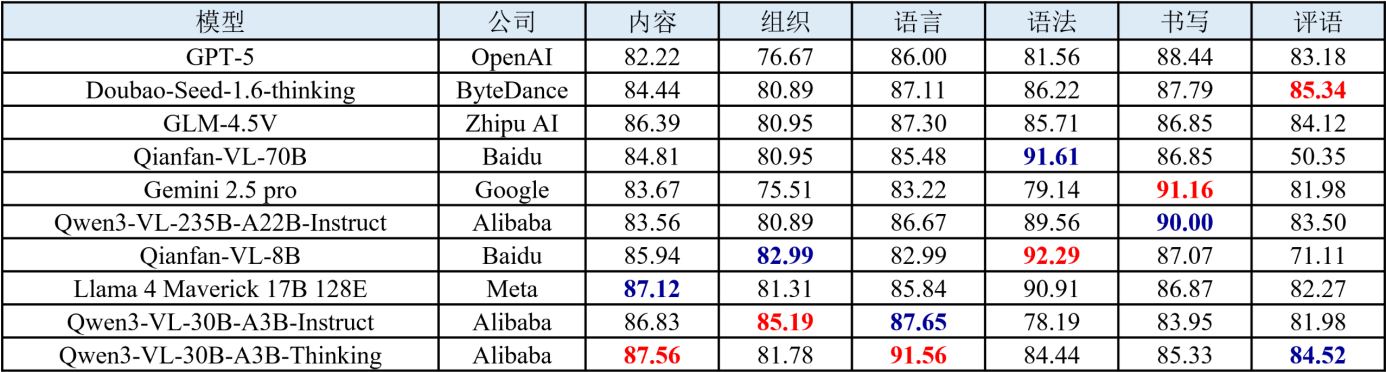
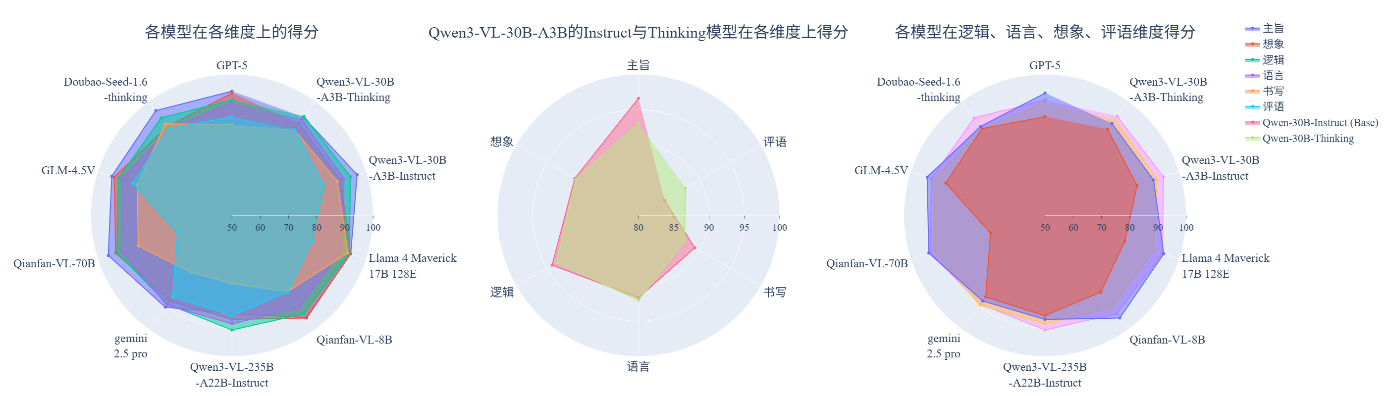
图 6 语文作文批改部分评测结果可视化展示
(1) 国产模型在中文场景优势明显,英语场景得到提升。在中文作文批改任务中,国产模型整体表现优于国际主流模型,尤其在主旨、逻辑与语言等核心维度上得分更高,充分体现出其对中文语料的深度适配和对整篇文章的语义理解。此外,国产模型在英语作文批改任务中的表现亦较往期有所提升。
(2) “思考”推理机制增强模型的评语生成能力。采用思维链推理机制的增强型模型,在评语生成维度上展现出性能提升。推理机制使模型能够在生成最终反馈前进行多步推理,从而改善评语的逻辑性、条理性与批判深度。
(3) 语言与逻辑维度表现稳健,想象与评语维度仍为关键短板。在语言、逻辑、语法等规则性和结构性较强的维度上,各模型均能维持较高得分,表明当前大模型在语言建模与逻辑关联方面的基础能力已相对成熟。然而,在想象、评语等维度需要更高层次抽象理解与创造性表达的维度上,模型间差距明显且整体表现偏弱。
6.学情分析
学情分析评测任务用于评测大模型分析学生学习情况的能力。评测任务的输入为学生考试数据,输出为待测大模型在知识点分析、掌握度分析、个性化学习建议可行性、丰富性及学情报告切合性等评测维度的分数。评测结果如下表所示。
表 16 数学学科学情分析的部分评测结果
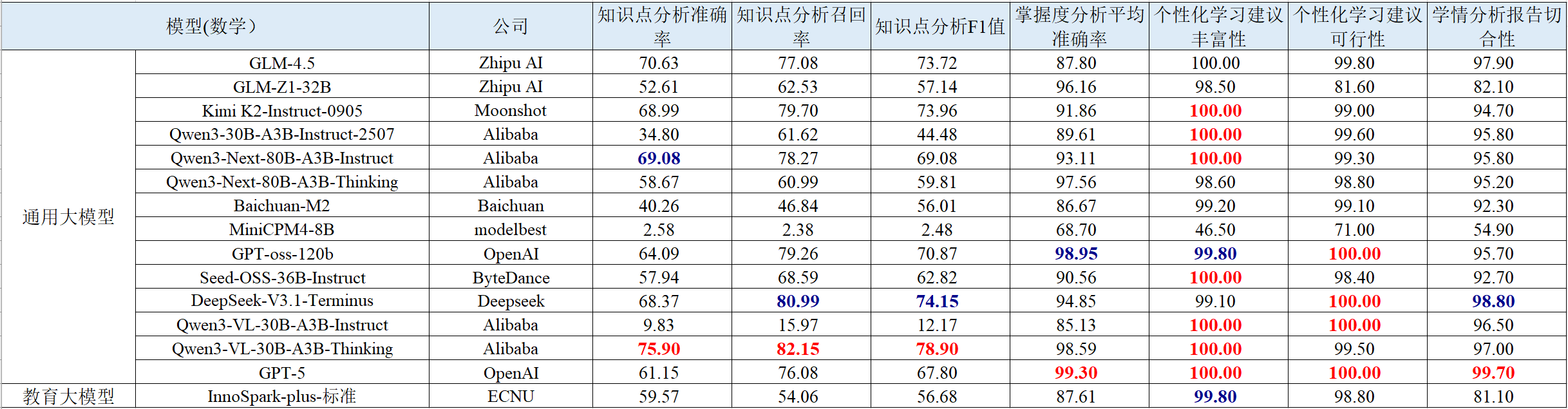

图 7 数学学科学情分析部分评测结果可视化展示
(1) 相较首期榜单,模型在个性化学习建议任务上性能提升。此次评测的多款模型在个性化学习建议相关维度上性能提升明显,其中Qwen系列即使在小规模参数量下依然发挥优异,这表明在目标明确、框架清晰的特定应用任务上,模型优化已取得一定进展,且模型能力不完全依赖于参数规模。
(2) 知识点分析维度仍为瓶颈。与一期榜单模型相比,此次评测模型在知识点分析相关任务上总体与其保持性能持平,知识点分析任务F1值尚未突破80%,存在较大可提升空间,这反映出对知识深层逻辑关系的精准剖析仍是当前模型的普遍瓶颈。
(3) 多数推理模型表现领先。多数推理类模型在三个子任务维度上的性能处于领先地位,给模型更多思考空间可以提高模型在学情分析类任务上的总体性能。改进模型的推理与思维链条是提升学情分析复杂任务上性能表现的潜在路径。

